Hierarchical Masked 3D Diffusion Model for Video Outpainting
News Updates

Abstract
Video outpainting aims to adequately complete missing areas at the edges of video frames. Compared to image outpainting, it presents an additional challenge as the model should maintain the temporal consistency of the filled area. In this paper, we introduce a masked 3D diffusion model for video outpainting. We use the technique of mask modeling to train the 3D diffusion model. This allows us to use multiple guide frames to connect the results of multiple video clip inferences, thus ensuring temporal consistency and reducing jitter between adjacent frames. Meanwhile, we extract the global frames of the video as prompts and guide the model to obtain information other than the current video clip using cross-attention. We also introduce a hybrid coarse-to-fine inference pipeline to alleviate the artifact accumulation problem. The existing coarse-to-fine pipeline only uses the infilling strategy, which brings degradation because the time interval of the sparse frames is too large. Our pipeline benefits from bidirectional learning of the mask modeling and thus can employ a hybrid strategy of infilling and interpolation when generating sparse frames. Experiments show that our method achieves state-of-the-art results in video outpainting tasks.
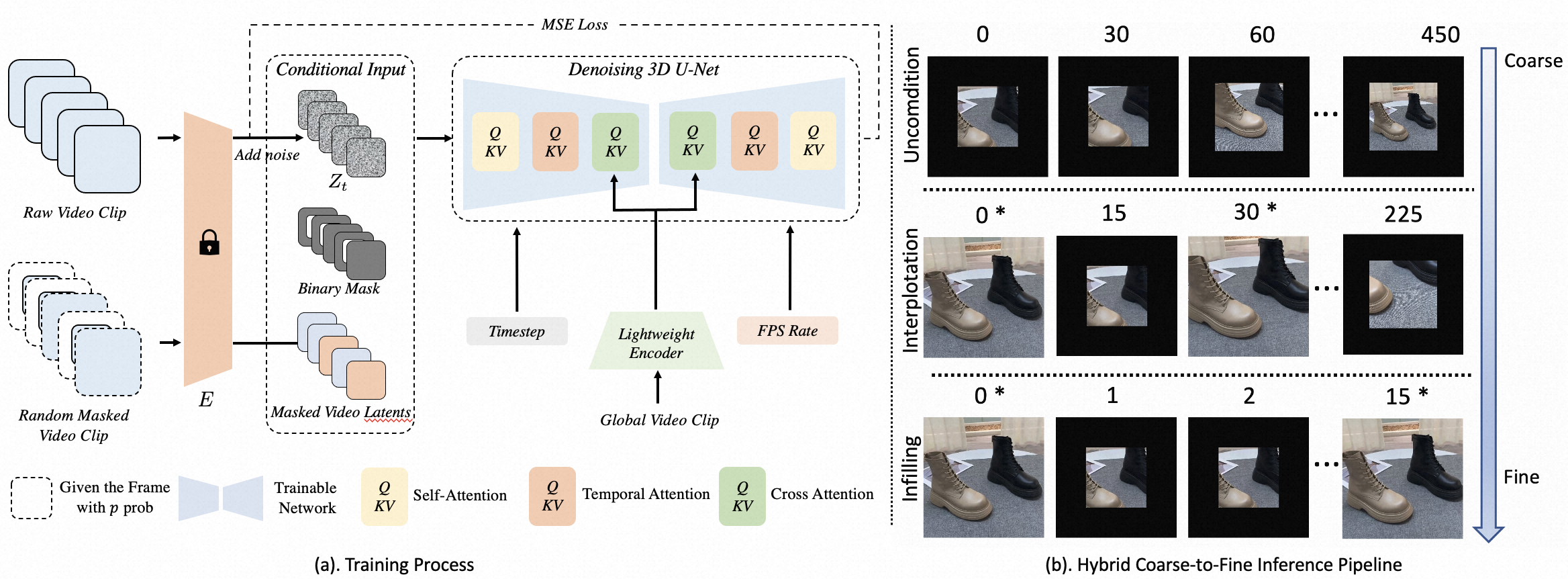
An illustration of our framework.
Video Results
BibTeX
@inproceedings{fan2023hierarchical,
title={Hierarchical Masked 3D Diffusion Model for Video Outpainting},
author={Fan, Fanda and Guo, Chaoxu and Gong, Litong and Wang, Biao and Ge, Tiezheng and Jiang, Yuning and Luo, Chunjie and Zhan, Jianfeng},
booktitle={Proceedings of the 31st ACM International Conference on Multimedia},
pages={7890--7900},
year={2023}
}